https://skillmemory.tistory.com/65
아마존 AWS Deep racer - 5월 Virtual Circuit League
https://skillmemory.tistory.com/64 아마존 AWS Deep racer - 모델 평가 evaluation AWS DeepRacer model을 생성하고 학습이 완료되었으면, 모델을 평가할 수 있습니다. 모델 생성 방법 글 참고 : https://skillm..
skillmemory.tistory.com
위 5월리그에서는 결과가 별로였으니, 6월리그를 위해서 모델을 개선해 보겠습니다.

모델 개선
5월에 사용했던 모델을 보면, Training iteration이 증가함에 따라서, Reward가 점점 증가되는 경향을 띄고 있었습니다.
아무래도 default training시간인 1시간보다 더 길게 training시간을 준다면, 좀더 성능이 향상될 것 같습니다.

아무래도 기존에 갖고 있는 차량의 action 설정이 discrete 라서 한계가 있는 것이 아닐까?
하는 생각이 들었습니다.
그래서, 이번에 받은 Retro car를 이용해서 새로운 continuous Action space를 사용하는 차량을 Build해서 사용해 보겠습니다.
왼쪽 메뉴에서 Your garage를 선택하면, 내가 보유하고 있는 설정별 차량들이 나타납니다.
새로 차량을 만들기 위해서, 오른쪽 위의 Build new vehicle버튼을 클릭합니다.

차량 이름을 입력합니다.
차량의 외모를 선택합니다.
차량 외모 선택후, Next버튼을 클릭하면, 차량의 센서 사양을 선택하는 화면이 나타납니다.
여기서는 기본으로 Camera를 선택했는데, 물체 피하기 리그나, 다른 차량과 경주하는 리그에 출전하기 위해서는 Stereo camera와 LIDAR sensor를 선택하는 것이 더 좋을 것입니다.

Next를 누르면, Action space설정 화면이 나타납니다.
Continuous action space는 각 action에 해당하는 범위를 설정하면, 그 사이의 모든 구간에 해당하는 action을 차량이 갖을 수 있습니다.

반면, Discrete action space로 설정하면,
각 action의 최대/최소 값과 변화량 단위를 설정하면, 차량이 갖을 수 있는 전체 action의 가지수가 아래 표처럼 나옵니다.

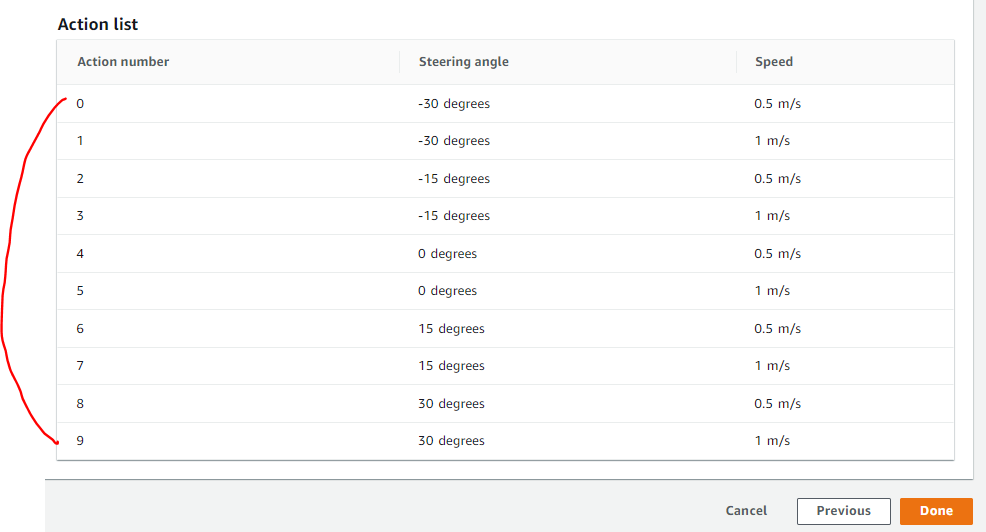
action을 세분화 하면 더 섬세한 제어를 할 수 있으니 좋을 것 같은데, Training 시간의 증가와 과최적화에 빠질 수 있는 위험도 있기 때문에, 실재 training 과 evaluation을 해보고 효과를 판단해 봐야겠습니다.
6월에 사용할 보상함수는, 3가지 기능을 사용하여 모델을 개선했습니다.
1. 트랙 중앙에서 벗어나는 정도에 따른 reward차이
2. 트랙 중앙에서의 거리에 따라서, Penalty에 사용할 speed, steering angle threshold가 변경되게 하여, 중앙에서 떨어진 위치에 따라서 필요한 action을 취하도록 함(급격한 커브 대응용)
3. 완주하면 reward 많이 줘서, 완주에 초점을 맞추게함
def reward_function(params):
'''
Example that penalizes steering, which helps mitigate zig-zag behaviors
'''
# Calculate 4 marks that are farther and father away from the center line
marker_1 = 0.1 * params['track_width']
marker_2 = 0.2 * params['track_width']
marker_3 = 0.3 * params['track_width']
marker_4 = 0.4 * params['track_width']
distance_from_center = params['distance_from_center']
steering_angle = params['steering_angle']
all_wheels_on_track = params['all_wheels_on_track']
speed = params['speed']
# Set dynamic thresholds based on distance_from_center
# Give higher reward if the car is closer to center line and vice versa
# Steering penality threshold, change the number based on your action space setting
# Set the speed threshold based your action space
if distance_from_center <= marker_1:
reward = 1
ABS_STEERING_THRESHOLD = 5
SPEED_THRESHOLD = 2.0
elif distance_from_center <= marker_2:
reward = 0.7
ABS_STEERING_THRESHOLD = 10
SPEED_THRESHOLD = 1.0
elif distance_from_center <= marker_3:
reward = 0.5
ABS_STEERING_THRESHOLD = 20
SPEED_THRESHOLD = 0.5
elif distance_from_center <= marker_4:
reward = 0.1
ABS_STEERING_THRESHOLD = 30
SPEED_THRESHOLD = 0.5
else:
reward = 1e-3 # likely crashed/ close to off track
ABS_STEERING_THRESHOLD = 40
SPEED_THRESHOLD = 0.1
# Penalize reward if the car is steering too much
if abs(steering_angle) > ABS_STEERING_THRESHOLD:
reward *= 0.5
if not all_wheels_on_track: # Penalize if the car goes off track
reward *= 1e-3
elif speed < SPEED_THRESHOLD: # Penalize if the car goes too slow
reward *= 0.5
else: # High reward if the car stays on track and goes fast
reward *= 1.0
# give a reward at each time of the completing a lap
if params['progress'] == 100 :
reward += 10000
return float(reward)
아래 github에 지속적으로 코드를 업데이트하고 있습니다.
https://github.com/kenrou625/LGES_Deepracer
kenrou625/LGES_Deepracer
LGES's Deepracer challenge project. Contribute to kenrou625/LGES_Deepracer development by creating an account on GitHub.
github.com
Training시 보상은 좀 들쭉 날쭉합니다...

model3의 evaluation결과, 트랙완주율이 좀 떨어지는 것 같은데, 일단 리그에 투입시켜 봅니다.


6월 리그 진행중 결과
일단, 지난 5월보다 순위가 훨씬 올라갔습니다!!


48위로 상위권으로 올라섰는데, 아마 위의 보상함수 개선포인트들 + continuous action space 조합의 결과가 아닌가 싶습니다.
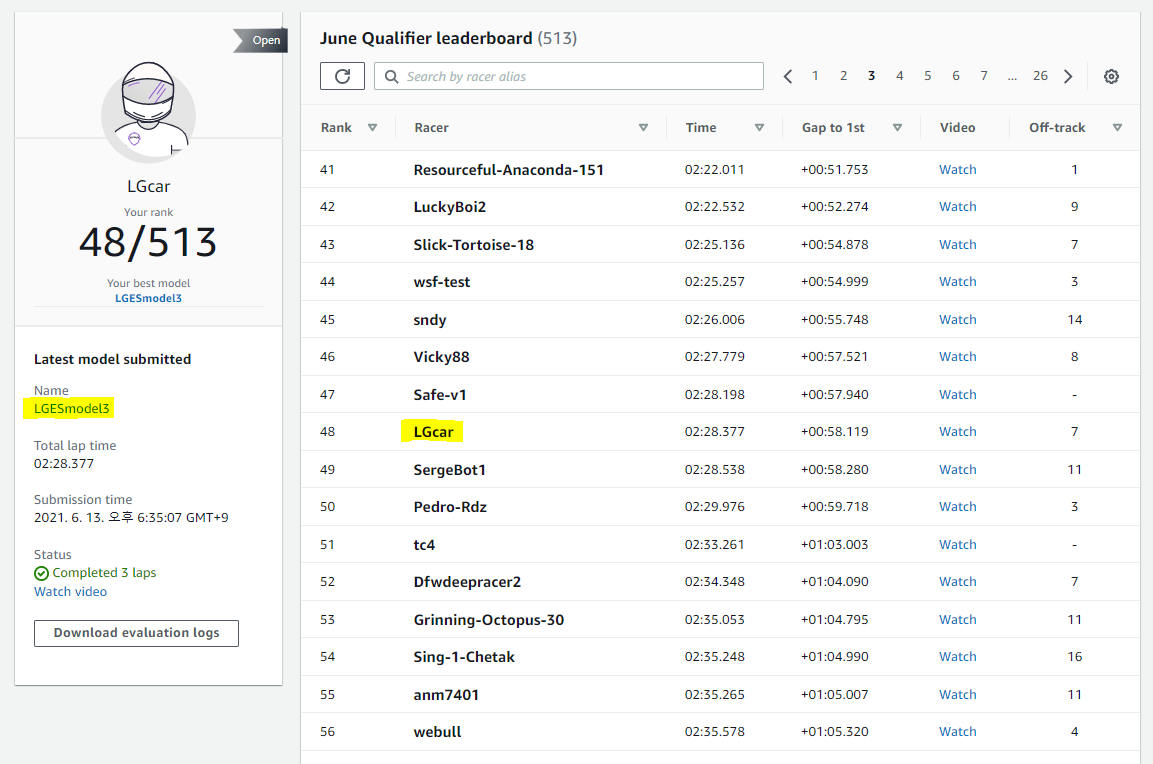
앞으로 16등에 들어야 Pro리그에 진출하니, 더 정진해야겠습니다!!

'AI & 머신러닝 coding skill' 카테고리의 다른 글
| 가상 PC 서버 window에서 OS 시간 및 언어 설정 (0) | 2022.04.03 |
|---|---|
| 아마존 AWS Deep racer - 7,8월 리그 결과, RC car 테스트 시작 (0) | 2021.12.21 |
| 아마존 AWS Deep racer - 6월 리그 결과, Pro division 승격! (0) | 2021.07.25 |
| 아마존 AWS DeepRacer - 강화학습 교육 이수증 (0) | 2021.06.15 |
| 아마존 AWS Deep racer - 5월 Virtual Circuit League (0) | 2021.06.13 |
| 아마존 AWS Deep racer - 모델 평가 evaluation (0) | 2021.05.31 |
| 아마존 AWS Deep racer - 모델 생성 (0) | 2021.05.30 |
| 아마존 AWS Deep racer - 강화학습 자율주행 RC카 (0) | 2021.04.26 |



