6월 리그에서 상위권에 입상하여, Pro Division으로 승격되었습니다!
1133명중에 105등이 되었습니다.


리그의 Leaderboard를 보면, Video의 watch를 클릭하면, 해당 Racer의 코스 주행 화면을 볼 수 있습니다.
그런데, 탑랭커들은 거의 트랙의 Best line을 지정해서 이 경로를 학습하는 방법을 쓰는 것 같습니다.
그래서 미리 앞의 코스를 아는 듯이 차량이 적절한 Out In Out 코스를 구사하면서 엄청나게 빠른 스피드로 진행하는 것을 볼 수 있습니다.
하지만, 이 트랙의 코스를 외우는 방법은 시뮬레이션 상에서 트랙내 차량의 (x, y)위치에 따른 최적 경로대로 주행하도록 학습하는 훈련이기 때문에, 다른 코스에서는 써먹지 못하고 트랙마다 다시 학습을 해야합니다.
더구나, Off-line에서는 차량위치는 센서로 알수없기 때문에, 최종 리그인 실재 트랙에서 실물 차량으로 주행하는 Off-line 대회에서는 사용할 수 없는 방법입니다.
이런 얍셉이 같은? 방법을 사용하는 Racer들에게 밀려서 아쉽지만, 우리는 Camera, LiDAR 센서만을 사용하여 우승할 수 있도록 노력해봐야겠습니다.

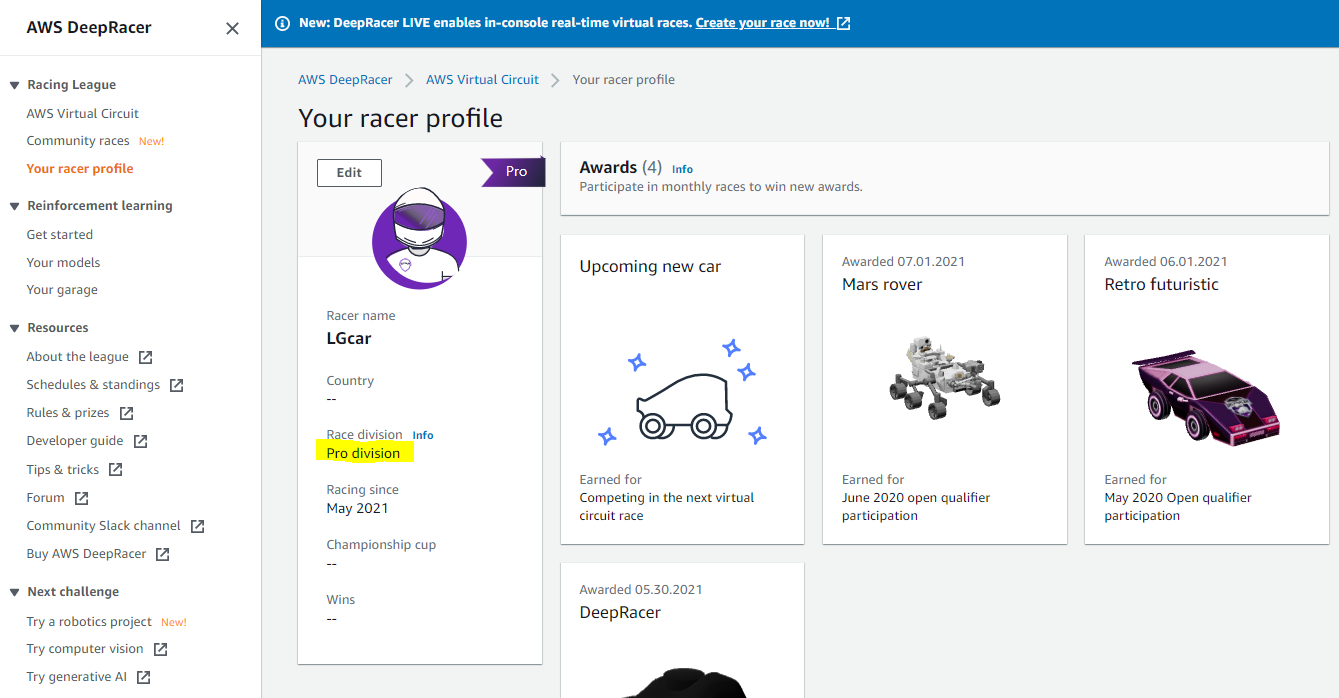
6월 리그 상품으로 아래 차량도 수여받았습니다. 매달 마다 다른 모양의 차량을 리그 참여 상품으로 줍니다.


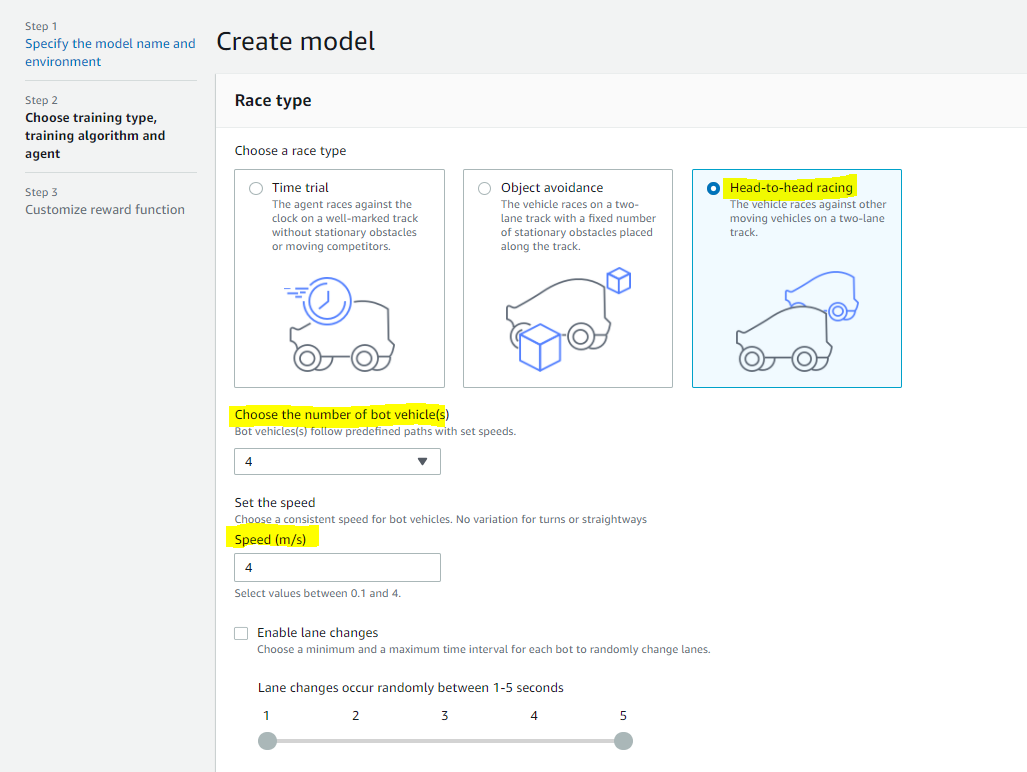
이제 7월에는 Pro Division에서 Head to Bot 형식으로 시합을 하게 됩니다.

Pro Division에서는 기존에 Open Division리그에서의 Time trial방식이 아닌, Head-to-bot 형식으로 트랙을 주행하게 됩니다.
트랙을 가장 빨리 돌아야하는 것은 동일하며, 다른 4개의 차량과 함께 주행을 하는 것이 추가된 점입니다.
이 4개의 차량 bot들은 2m/s의 속도로 차선이동없이 각자 주행하고 있는데, 이 차량을 내 Deepracer가 부딛히게 되면, Penalty로 5초를 받게 됩니다.
따라서, 최대한 같이 주행하는 bot들을 피하면서, 빨리 트랙을 완주할 수 있도록 되어야합니다.

기존 Open divion에서 사용했던 Single camera, continuous action space를 사용한 LGESmodel3를 그대로 사용해서 리그에 참여해봤는데, 결과는 별로입니다.



트랙과 Racer방식만 Pro division에서 사용하는 트랙과 Head-to-bot경기 방식에서 학습을 시켰습니다.
학습 score는 그런대로 괜찮았는데, 실재 리그 주행 화면을 보면, 다른 차량과도 부딛히고, 트랙도 계속 벗어나고 있었습니다.

기존의 single camera만 갖고 있는 차량세팅으로 학습한 모델을 아무래도 한계가 있는 것 같습니다. (거리 인식 센서도 없으니)

그래서, 이번에 상품으로 받은 화성탐사차량을 Mulit camera, LiDAR, continuous action space차량으로 설정하고나서, 새로운 Head-to-bot경기용 모델을 생성하기로 했습니다.
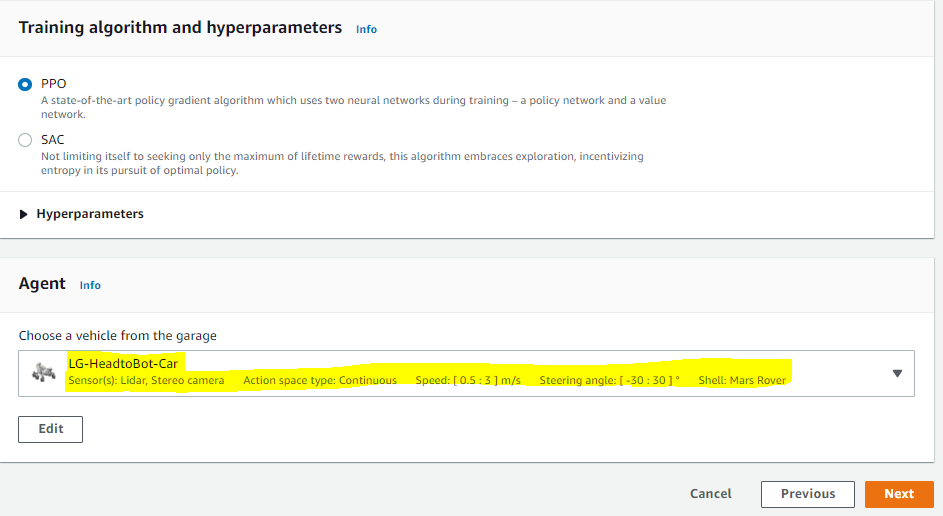
기존에 Time trial주행 방식에서 사용했던 reward function을 그대로 사용하지는 못하고, object_distance와 같은 object위치와 관련된 센서 파라미터들을 추가로 사용해야합니다.
일단 기존에 예제로 있는 Head-to-bot용 예제 코드를 그대로 사용해보도록 하겠습니다.

아래는 Head-to-bot용 reward function예제코드입니다.
def reward_function(params):
'''
Example of rewarding the agent to stay inside two borders
and penalizing getting too close to the objects in front
'''
all_wheels_on_track = params['all_wheels_on_track']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
objects_distance = params['objects_distance']
_, next_object_index = params['closest_objects']
objects_left_of_center = params['objects_left_of_center']
is_left_of_center = params['is_left_of_center']
# Initialize reward with a small number but not zero
# because zero means off-track or crashed
reward = 1e-3
# Reward if the agent stays inside the two borders of the track
if all_wheels_on_track and (0.5 * track_width - distance_from_center) >= 0.05:
reward_lane = 1.0
else:
reward_lane = 1e-3
# Penalize if the agent is too close to the next object
reward_avoid = 1.0
# Distance to the next object
distance_closest_object = objects_distance[next_object_index]
# Decide if the agent and the next object is on the same lane
is_same_lane = objects_left_of_center[next_object_index] == is_left_of_center
if is_same_lane:
if 0.5 <= distance_closest_object < 0.8:
reward_avoid *= 0.5
elif 0.3 <= distance_closest_object < 0.5:
reward_avoid *= 0.2
elif distance_closest_object < 0.3:
reward_avoid = 1e-3 # Likely crashed
# Calculate reward by putting different weights on
# the two aspects above
reward += 1.0 * reward_lane + 4.0 * reward_avoid
return reward
이 예제코드로 학습한 모델의 결과를 보면서, 다른 차량 bot(object)들을 피하는 모습을 보고, 효과가 있다고 판단되는 수준까지 object를 피하는 코드부분을 개선할 예정입니다.
그리고 나서, 어느 정도 object를 피하는 수준이 달성되면, 기존에 open division에서 사용했던 트랙주행코드 + 개선점 보완(트랙 중앙에서의 거리 및 차량각도에 따른 핸들링 각도/속도 보상 로직 추가, 등등)하여 7월 Pro division 리그에서 역전을 꾀해보겠습니다.

'AI & 머신러닝 coding skill' 카테고리의 다른 글
| 머신러닝 - 회귀(Regression) 사이킷런 (0) | 2022.05.23 |
|---|---|
| 머신러닝 - 회귀(Regression) (0) | 2022.05.23 |
| 가상 PC 서버 window에서 OS 시간 및 언어 설정 (0) | 2022.04.03 |
| 아마존 AWS Deep racer - 7,8월 리그 결과, RC car 테스트 시작 (0) | 2021.12.21 |
| 아마존 AWS DeepRacer - 강화학습 교육 이수증 (0) | 2021.06.15 |
| 아마존 AWS Deep racer - 모델 reward function 개선, 차량 action space 설정, 6월 리그 진행중 (0) | 2021.06.13 |
| 아마존 AWS Deep racer - 5월 Virtual Circuit League (0) | 2021.06.13 |
| 아마존 AWS Deep racer - 모델 평가 evaluation (0) | 2021.05.31 |



