반응형
K-Means 클러스터링
K-Means 클러스터링은 가장 간단하고 널리 사용되는 클러스터링 알고리즘 입니다.
K-Means 클러스터링은 데이터의 영역을 대표하는 Cluster-center(중심점)을 찾아가며 데이터를 클러스터에 할당합니다.
이번 실습에서는 사이킷런에 구현된 K-Means 클러스터링 모델을 불러와 클러스터링 결과를 시각화를 통해 확인해보겠습니다.
K-Means 클러스터링을 위한 사이킷런 함수/라이브러리
- from sklearn.cluster import KMeans: K-Means 클러스터링을 위한 모델을 불러옵니다.
- KMeans(init, n_clusters, random_state) : K-Means 클러스터링 모델을 정의합니다.
- init : 중심점 초기화 방법 설정(‘random’ 으로 설정할 경우 랜덤으로 중심점을 초기화함)
- n_clusters : 군집의 개수, 즉 군집 중심점의 개수
- random_state : 일관된 결과 확인을 위한 설정값
- [Model].fit(data) : data에 대한 클러스터링을 수행합니다.
- [Model].labels_ : 각 데이터가 속한 군집 중심점 label(클러스터링 결과)를 반환합니다.
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# 데이터를 불러오고, 데이터 프레임 형태로 만든 후 반환하는 함수입니다.
def load_data():
iris = load_iris()
irisDF = pd.DataFrame(data = iris.data, columns = iris.feature_names)
irisDF['target'] = iris.target
return irisDF
"""
1. K-means 클러스터링을
수행하는 함수를 구현합니다.
Step01. K-Means 객체를 불러옵니다.
군집의 개수는 3,
중심점 초기화는 랜덤,
random_state = 100으로 설정합니다.
Step02. K-means 클러스터링을 수행합니다.
클러스터링은 정답이 없는 데이터를
사용하기 때문에 target 변수를 제거한
데이터를 학습시켜줍니다.
Step03. 군집화 결과 즉, 각 데이터가 속한 군집
중심점들의 label을
iris 데이터 프레임에 추가합니다.
"""
def k_means_clus(irisDF):
kmeans = KMeans(init = 'random', n_clusters=3)
kmeans.fit(irisDF.drop('target', axis=1))
irisDF['cluster'] = kmeans.labels_
# 군집화 결과를 보기 위해 groupby 함수를 사용해보겠습니다.
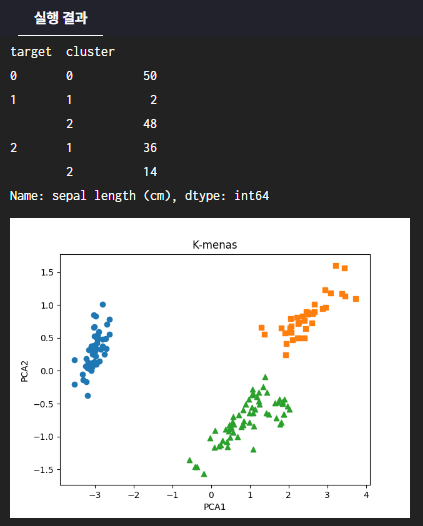
iris_result = irisDF.groupby(['target','cluster'])['sepal length (cm)'].count()
print(iris_result)
return iris_result, irisDF
# 군집화 결과 시각화하기
def Visualize(irisDF):
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(irisDF)
irisDF['pca_x'] = pca_transformed[:,0]
irisDF['pca_y'] = pca_transformed[:,1]
# 군집된 값이 0, 1, 2 인 경우, 인덱스 추출
idx_0 = irisDF[irisDF['cluster'] == 0].index
idx_1 = irisDF[irisDF['cluster'] == 1].index
idx_2 = irisDF[irisDF['cluster'] == 2].index
# 각 군집 인덱스의 pca_x, pca_y 값 추출 및 시각화
fig, ax = plt.subplots()
ax.scatter(x=irisDF.loc[idx_0, 'pca_x'], y= irisDF.loc[idx_0, 'pca_y'], marker = 'o')
ax.scatter(x=irisDF.loc[idx_1, 'pca_x'], y= irisDF.loc[idx_1, 'pca_y'], marker = 's')
ax.scatter(x=irisDF.loc[idx_2, 'pca_x'], y= irisDF.loc[idx_2, 'pca_y'], marker = '^')
ax.set_title('K-menas')
ax.set_xlabel('PCA1')
ax.set_ylabel('PCA2')
fig.savefig("plot.png")
elice_utils.send_image("plot.png")
def main():
irisDF = load_data()
iris_result, irisDF = k_means_clus(irisDF)
Visualize(irisDF)
if __name__ == "__main__":
main()

반응형
'AI & 머신러닝 coding skill' 카테고리의 다른 글
| 머신러닝 - t-SNE (0) | 2022.05.23 |
|---|---|
| 머신러닝 - 주성분 분석(PCA) (0) | 2022.05.23 |
| 머신러닝 Clustering - K-Means VS GMM (0) | 2022.05.23 |
| 머신러닝 Clustering - Gaussian Mixture Model (GMM) (0) | 2022.05.23 |
| 머신러닝 분류 - 로지스틱 회귀(Logistic Regression) (0) | 2022.05.23 |
| 머신러닝 - 회귀 알고리즘 평가 지표- R_squared (0) | 2022.05.23 |
| 머신러닝 - 회귀 알고리즘 평가 지표- MSE, MAE (0) | 2022.05.23 |
| 머신러닝 - 회귀 알고리즘 평가 지표- RSS (0) | 2022.05.23 |



