반응형
SVM(Support Vector Machine)
서포트 벡터 머신은 높은 성능을 보여주는 대표적인 분류 알고리즘입니다.
특히 이진 분류를 위해 주로 사용되는 알고리즘으로, 각 클래스의 가장 외곽의 데이터들 즉, 서포트 벡터들이 가장 멀리 떨어지도록 합니다.
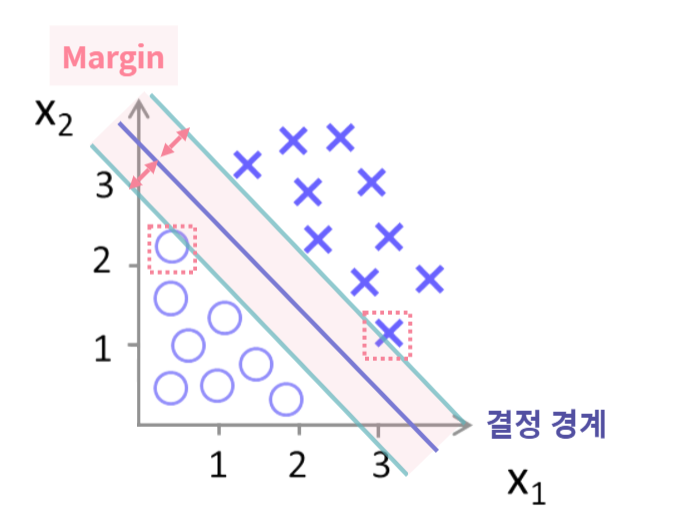
이번 실습에서는 0과 1로 분류되어 있는 데이터 셋에서, SVM을 사용하여 데이터가 올바르게 분류되는지 확인해보겠습니다.
SVM을 위한 사이킷런 함수/라이브러리
- from sklearn.svm import SVC : SVM 모델을 불러옵니다.
- SVC(): SVM 모델을 정의합니다.
- [Model].fit(x, y): (x, y) 데이터셋에 대해서 모델을 학습시킵니다.
- [Model].predict(x): x 데이터를 바탕으로 예측되는 값을 출력합니다.
Tips!
pandas의 DataFrame에 쓸 수 있는 drop 메소드를 활용하면 DataFrame에서 원하는 column(열)의 이름을 통해 해당 column을 삭제할 수 있습니다.

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
"""
1. data 폴더 내에 있는 dataset.csv파일을 불러오고,
학습용 데이터와 테스트용 데이터를 분리하여
반환하는 함수를 구현합니다.
Step01. pandas의 read_csv() 함수를 이용하여
data 폴더 내에 있는 dataset.csv파일을
불러옵니다.
Step02. 데이터 X와 y를 분리합니다.
데이터 폴더에 있는 dataset.csv 파일을
확인하고,
X 데이터와 y 데이터를 분리하여 각 변수에
저장합니다.
"""
def load_data():
data = pd.read_csv('data/dataset.csv')
X = data.drop('Class', axis=1)
y = data['Class']
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 0)
print(X, y)
return train_X, test_X, train_y, test_y
"""
2. SVM 모델을 불러오고,
학습용 데이터에 맞추어 학습시킨 후,
테스트 데이터에 대한 예측 결과를 반환하는 함수를
구현합니다.
Step01. SVM 모델을 정의합니다.
Step02. SVM 모델을 학습용 데이터에 맞추어
학습시킵니다.
Step03. 학습된 모델을 이용하여
테스트 데이터에 대한 예측을 수행합니다.
"""
def SVM(train_X, test_X, train_y, test_y):
svm = SVC()
svm.fit(train_X, train_y)
pred_y = svm.predict(test_X)
return pred_y
# 데이터를 불러오고, 모델 예측 결과를 확인하는 main 함수입니다.
def main():
train_X, test_X, train_y, test_y = load_data()
pred_y = SVM(train_X, test_X, train_y, test_y)
# SVM 분류 결과값을 출력합니다.
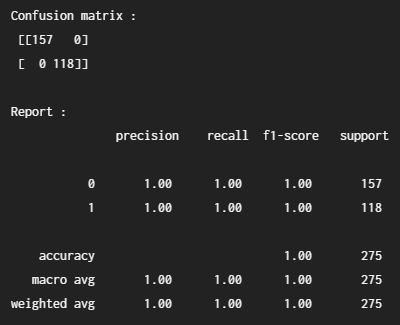
print("\nConfusion matrix : \n",confusion_matrix(test_y,pred_y))
print("\nReport : \n",classification_report(test_y,pred_y))
if __name__ == "__main__":
main()


반응형
'AI & 머신러닝 coding skill' 카테고리의 다른 글
| 머신러닝 분류 - 정확도(accuracy), 정밀도(precision), 재현율(recall) (0) | 2022.05.24 |
|---|---|
| 머신러닝 분류 - 혼동 행렬(Confusion matrix) (0) | 2022.05.24 |
| 머신러닝 분류 - 사이킷런을 활용한 나이브 베이즈 분류 (0) | 2022.05.24 |
| 머신러닝 분류 - 나이브 베이즈 분류 (0) | 2022.05.24 |
| 머신러닝 Decision tree - 앙상블(Ensemble) 기법 - Bagging (0) | 2022.05.24 |
| 머신러닝 Decision tree - 앙상블(Ensemble) 기법 - Voting (0) | 2022.05.24 |
| 머신러닝 의사결정 나무(DecisionTree Classifier) - 분류 (0) | 2022.05.24 |
| 머신러닝 의사결정 나무(DecisionTree Regressor) - 회귀 (0) | 2022.05.24 |



